Vergleich zwischen ChatGPT o3-mini und DeepSeek R1 (online). Aufgabestellung: Erstellung eines Tetris Games.
Der Programmcode (HTML und JavaScript) umfasst bei ChatGPT o3-mini 333 Zeilen und bei DeepSeek R1 188 Zeilen. Wie effizient und schlau der jeweilige Programmcode ist, habe ich nicht näher analysiert.
Für die DeepSeek Version benötigte ich zwei Prompts (siehe Screenshot). Zudem springt bei der DeepSeek Version das Spielfeld vertikal ab und zu um ein paar Pixel. Insgesamt hat ChatGPT o3-mini etwas die Nase vorn. Es genügte ein Prompt um ein gutes Ergebnis zu erzielen.
Natürlich ist Tetris nicht die große Herausforderung für aktuelle KI-Modelle. Dieser Klassiker ist quasi ein Kulturgut und jedes Modell wird an der Logik trainiert worden sein. Daher kann man nur bedingt ableiten, wie gut die jeweiligen Modelle für die Softwareentwicklung von komplexeren Anforderungen funktionieren.

DeepSeek R1 befindet sich laut Benchmarks ungefähr auf dem Niveau von ChatGPT o1. Aktuell dauert es ca. drei bis sechs Monate, bis die OpenSource Modelle auf das Niveau der kommerziellen Flagschiffe kommen. Im Sommer ’25 könnte also bspw. DeepSeek ein Modell auf den Markt bringen, dass die Leistungsfähigkeit von ChatGPT o3 liefert.
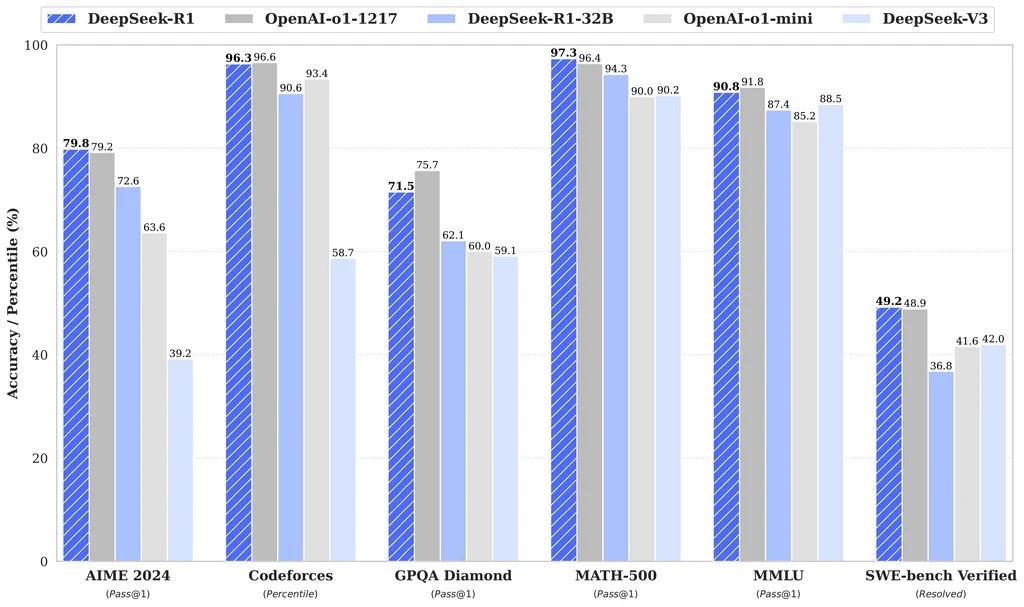
Die Denkstrategien großer Modelle kann auf kleinere Modelle übertragen (distilliert) werden, was zu einer besseren Leistung führt, als wenn kleinere Modelle direkt durch Reinforcement Learning trainiert werden. DeepSeek-R1 und seine API werden der Forschungsgemeinschaft zur Verfügung gestellt, um die Distillation besserer kleinerer Modelle zu ermöglichen. Basierend auf den OpenSource Modellen Qwen2.5 und Llama3 wurden verschiedene kleine Modelle (1,5B bis 70B Parameter) trainiert und als Open-Source-Modelle veröffentlicht.
DeepSeek-R1-Distill Models
| Model | Base Model | Download |
|---|---|---|
| DeepSeek-R1-Distill-Qwen-1.5B | Qwen2.5-Math-1.5B | ???? HuggingFace |
| DeepSeek-R1-Distill-Qwen-7B | Qwen2.5-Math-7B | ???? HuggingFace |
| DeepSeek-R1-Distill-Llama-8B | Llama-3.1-8B | ???? HuggingFace |
| DeepSeek-R1-Distill-Qwen-14B | Qwen2.5-14B | ???? HuggingFace |
| DeepSeek-R1-Distill-Qwen-32B | Qwen2.5-32B | ???? HuggingFace |
| DeepSeek-R1-Distill-Llama-70B | Llama-3.3-70B-Instruct | ???? HuggingFace |
Diese Modelle können durchaus auch auf dem eigenen PC ausgeführt werden, je nach Ausstattung natürlich. Das kleinste Modell mit 1,5 Mrd. Parametern sollte auf jeden PC ausführbar sein. So kann man z. B. über Ollama auf dieses Modell zugreifen und z. B. in VS Code einbinden. Wie das geht, habe ich in diesem Artikel erklärt. Möchte man die größeren Modelle ausführen, wird man um eine gute Grafikkarte nicht drumherum kommen. Auf einer GeForce mit 24GB sollte das Qwen-32B Modell noch ausreichend gut laufen. Das Original-Modell von DeepSeek R1 mit 685 Mrd. Parametern erfordert deutlich größere Kapazität, was jenseits des Heimbereichs im Professionellen Segment, vulgo Cloud angesiedelt sein dürfte.