Microsofts KI-basierter Assistent Copilot ist schon seit einiger Zeit ganz klassisch als Chatbot in Bing verfügbar. Mittlerweile kann Copilot aber auch über das Microsoft Copilot Studio als spezialisierter KI-Agent für die Steuerung von Anwendungen eingerichtet werden. Über solche innovativen Agenten lassen sich besonders gut serielle Tätigkeiten automatisieren, was zu effizienteren Geschäftsprozessen führt. Aber auch in der Softwareentwicklung wird Copilot eingesetzt. Der Github Copilot wird z. B. in einer Entwicklungsumgebung wie VS Code integriert und kann als Coding Assistent Codevorschläge anzeigen, Fehler debuggen oder Programmcode kommentieren. Das ist quasi ein chatGPT direkt im Coding-Editor. Um Copilot nutzen zu können ist allerdings ein Benutzer-Konto bei Github notwendig, und alles, was im Code-Editor passiert, wird an den Github-Server gesendet, um ihn zu analysieren und Vorschläge zu generieren. Zudem sammelt Github Copilot regelmäßig Telemetriedaten, um diese auszuwerten. Für Hobby- oder Open-Source-Projekte mag dieser freigiebige Umgang mit Sourcecodes und Daten weniger problematisch sein, im Unternehmensumfeld ist dies aber u. U. als kritisch anzusehen.
Es gibt allerdings eine Möglichkeit, so einen KI-Assistenten lokal, also On-Premise zu betreiben und in die eigene Entwicklungsumgebung zu integrieren. Alles, was man dazu benötigt, ist die LLM Engine Ollama, ein LLM Model und ein passendes Plug-in für die Entwicklungsumgebung. Im Folgenden werden wir die einzelnen Schritte durchgehen um ein lokales LLM Model als Code-Agent in VS Code zu integrieren. Was ihr benötigt, ist:
- Visual Studio Code
- CodeGPT Plugin
- Ollama
- Llama 3.2 LLM Model
Schritt 1: Wer ihn noch nicht installiert hat sollte als erstes Visual Studio Code herunterladen und installieren
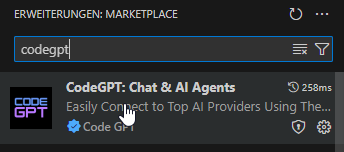
Schritt 2: In VS Code installiert ihr das Plug-in CodeGPT. Geht dazu links im Seitenmenü auf Erweiterungen und gebt im Suchfeld: CodeGPT ein (Es gibt mehrere Plug-ins mit Namen CodeGPT. Achtet darauf, das Plugin von codegpt.co auszuwählen, das unten im Screenshot angezeigt wird):
Schritt 3: Nun müsst ihr das Tool Ollama herunterladen und installieren. Ollama hat übrigens nichts mit dem LLM Model Lllama von Meta zu tun. Ollama ist ein Open-Source-Tool, das von Jeffrey Morgan entwickelt wurde und das zur Ausführung von Large Language Models auf dem eigenen Computer dient.

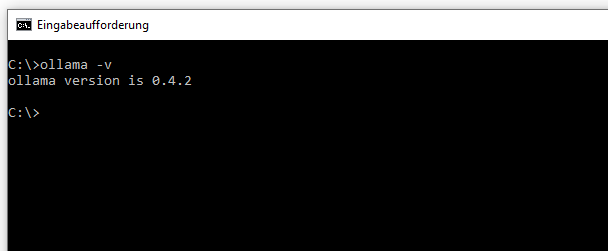
Wenn die Installation durchgeführt wurde, könnt ihr mit folgendem Kommando unter der Konsole testen, ob Ollama läuft: ollama –version oder ollama -v.
Schritt 4: Download eines LLMs und Integration in VS Code.
Es gibt verschiedene Möglichkeiten, ein LLM auf den lokalen Rechner zu laden. Dabei stellt sich zunächst die Frage, woher bekommt man so ein Sprachmodell? Eine beliebte Quelle ist das Repository Huggingface. Dabei handelt es sich um eine Plattform für Machine Learning, wo die KI-Community eine Vielzahl von Datensätzen, Tools und eben Large Language Models zur Verfügung stellt. Von dort können Sprachmodelle z. B. im GGUF Format direkt heruntergeladen werden. Eine andere Möglichkeit wäre die Verwendung der Hugging Face CLI, um über die Konsole Modelle herunterzuladen. Huggingface bietet eine riesige Anzahl an spezialisierten Sprachmodellen. Man kann aber auch über Ollama selbst Sprachmodelle herunterladen, wobei Ollama sein eigenes Repository nutzt. Mit dem Konsole Kommando ollama run llama3.2 würde man das zur Zeit aktuelle Model Llama3.2 runterladen und in Ollama ausführen.
Wir haben es aber noch leichter, denn wir verwenden das VS Code Plugin CodeGPT und über dieses integrieren wir nicht nur das LLM Model in VS Code, sondern können es direkt darüber auch herunterladen. Geht dazu in VS Code in die Erweiterung CodeGPT und öffnet den Dialog. Dort gibt es ein Dropdown-Feld, über das man die gewünschte KI auswählen kann. Es gibt dort eine Liste mit den üblichen Online-Services, wie Anthropic, Azure, Grok oder dem Platzhirsch OpenAI. Falls ihr euch von einem dieser Dienstleister einen API-Key geholt habt, könnt ihr diesen hier eintragen, aber dann werden die Daten eben wieder online übertragen. Wir bleiben lokal und wählen in der Liste als Provider Ollama aus.
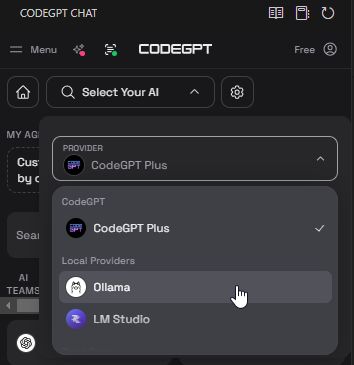
Unter dem ausgewählten Provider gibt es ein weiteres Dropdown-Feld mit den LLM-Modellen, die für Ollama zur Verfügung stehen. Hier wählt ihr das Model llama3.2:3b aus.
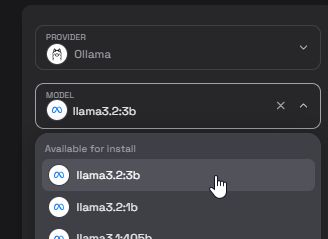
Nun müsst ihr noch auf den Download Button klicken, um das LLM Model vom Repository herunterzuladen.
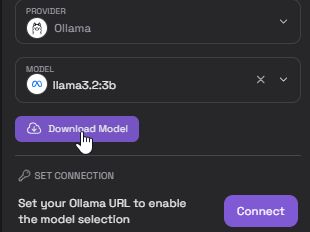
Das war es schon! Jetzt habt ihr einen lokal installierten Coding Buddy und ihr könnt diesen auch gleich austesten. Öffnet eine Datei, z. B. eine HelloWorld.py für Python Code. Dann könnt ihr im Textfenster von CodeGPT euren Prompt schreiben, so wie ihr das von chatGPT kennt.
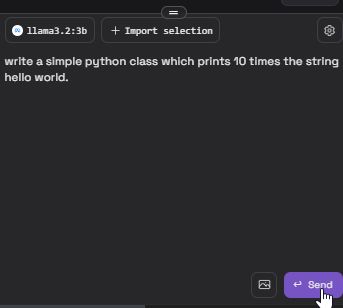
Nachdem der Prompt gesendet wurde, ruft das CodeGPT Plugin die lokal installierte Ollama Engine auf, welche das auswählte llama3.2:3b Model nutzt, um den Prompt zu bearbeiten. Das kann eine Weile dauern, je nach Aufgabenstellung und natürlich der Performance des Rechners. Wer einen modernen und schnellen PC, am besten mit NVIDIA Karte (12GB wird’s interessant) sein Eigen nennen kann, hat an dieser Stelle deutlich mehr Spaß als derjenige mit einem 8GB Ram Notebook. Auf einem PC mit z. B. einem Intel-Prozessor der 7. oder 8. Generation kann man aber durchaus schon mit dem lokalen LLM arbeiten.
Das Ergebnis auf unsere Prompt-Anfrage wird im CodeGPT Fenster ausgegeben. An der Stelle kann man den Chat weiterführen, oder man kann auch direkt den Code in den Editor übernehmen. Ob der Programmcode nun besonders elegant oder schlau ist, hängt natürlich davon ab, wie gut unser Model performed.
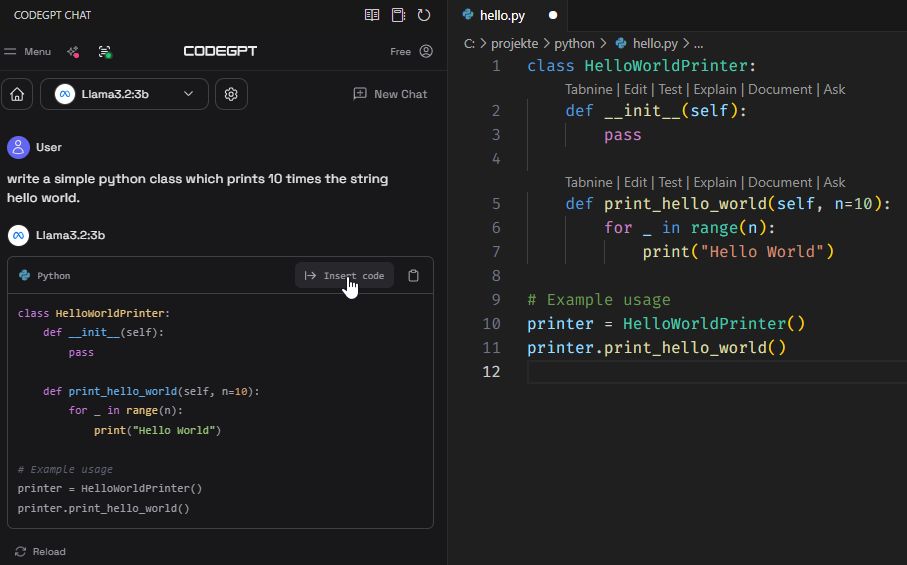
Wie man sieht, kann man so einen Code-Assistenten relativ leicht lokal betreiben und in den Programmeditor einbinden. Unser Sourcecode und evtl. sensible Daten bleiben auf unserem Rechner und obendrein sparen wir uns noch eine kostenpflichtige Subscription wie bei Github Copilot. Die Open-Source Sprachmodelle werden zunehmend leistungsfähiger. Das LLM Qwen2.5-Coder-32B ist beispielsweise auf Programmcode optimiert und liegt im Vergleich je nach Programmiersprache fast gleichauf mit Modellen wie GPT-4o. Bei manchen Programmiersprachen hat es sogar die Nase vorn. Der McEval Benchmark dient zur Bewertung von Code-Fähigkeiten großer Sprachmodelle. Er deckt 40 Programmiersprachen ab und umfasst insgesamt 16.000 Tests. Enthalten sind Aufgaben wie z. B. Code-Generierung, Code-Erklärung oder Code-Vervollständigung. Nachfolgend ein Benchmark-Vergleich verschiedener Modelle, darunter GPT-4o und Qwen2.5-Coder-32B:
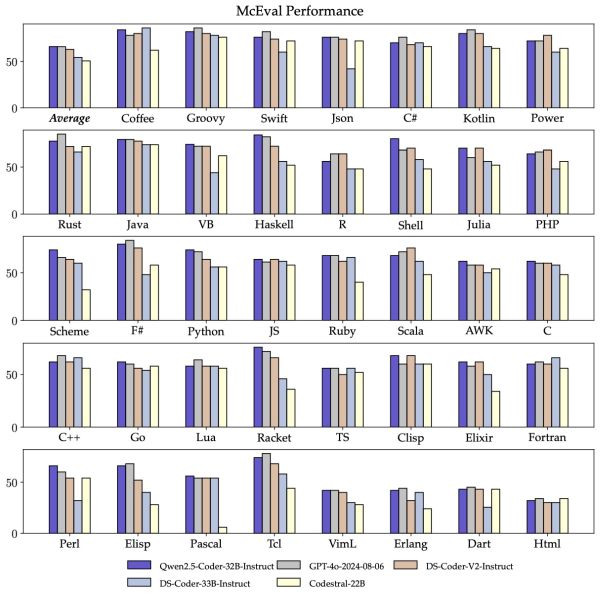
Ihr könnt über das CodeGPT Plugin auch das Qwen2.5-Code Modell herunterladen, auch in einer kleineren Variante als 32B, was bei schwächeren PCs Sinn macht. In den kommenden Jahren dürfte das Thema lokale generative KI wie ein Open Source LLM immer häufiger ein wichtiger Anwendungsfall werden. Die Hardwareanbieter, wie Avigilon oder NVIDIA stellen sich auf diesen Trend bereits ein und bieten spezielle KI-Appliances für den On-Premise Betrieb an. Auch für den Homeoffice-Anwender oder dem Hobby-Programmierer könnte es in Zukunft eine Überlegung Wert sein, in einen entsprechend ausgestatteten PC zu investieren, wenn er lokale KI-Lösungen sinnvoll nutzen möchte.